Eind mei heeft Google de tool ‘Fetch as Google‘ binnen Google Webmaster Tools enorm verbeterd door het mogelijk te maken om de pagina in zijn geheel te ‘renderen’. Deze aanpassing betekent dat je kunt bekijken hoe Googlebot je pagina’s ziet, inclusief het uitvoeren van de CSS- en JavaScript-bestanden.
Deze stap geeft aan dat Google steeds intelligenter wordt in het doorzoeken van CSS-en JavaScript. Door de pagina’s te fetchen kunnen webmasters nu nog beter identificeren waar op de pagina zich fouten voordoen die de doorzoekbaarheid van websites negatief beïnvloeden.
Wat is ‘Fetchen als Google’?
Het valt mij op dat deze tool nauwelijks bekend is bij veel webmasters. In ieder geval maken mijn klanten maar zelden gebruik van deze waardevolle tool. Fetchen als Google is in eerste in eerste instantie in het leven is geroepen om de doorzoekbaarheid van websites te controleren. Vanzelfsprekend kan er onderscheid worden gemaakt tussen desktop en mobiele pagina’s.
Een andere reden om pagina’s te fetchen is de functie om deze pagina’s direct in te dienen bij de Google index. Als webmaster, SEO of content marketeer kun je deze functie gebruiken om je content binnen enkele ogenblikken (!) in de Google index te krijgen. Ook als er net veel wijzigingen zijn aangebracht op de website, zoals bij een redesign of ingrijpende SEO-aanpassingen, worden via deze weg direct in Google opgenomen.
Let wel: Google geeft geen garantie dat alle aanpassingen ook daadwerkelijk als zodanig worden weergegeven in de SERP’s.
Reden genoeg voor iedere webmaster om dit verborgen pareltje vandaag nog te gebruiken! Mocht je nog niet overtuigd zijn, hieronder een tweetal voorbeelden hoe ik deze tool op Impactful.nl heb gebruikt.
Voorbeeld 1: Fetchen en weergeven als Google
In dit voorbeeld heb ik de homepage van Impactful.nl opgehaald. Zie hieronder het resultaat en een lijst met bronnen die Googlebot niet kon ophalen.
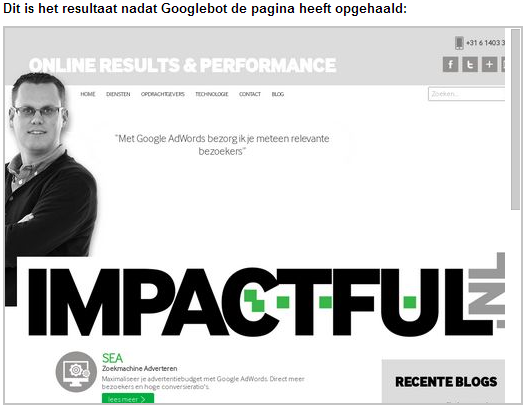
Geblokkeerde bronnen:
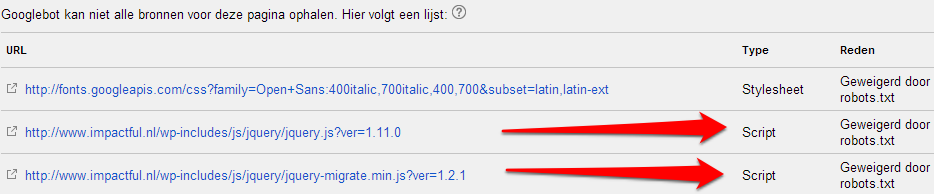
Uit het eerste screenshot valt op te maken dat het achtergrondplaatje niet wordt ingeladen. En uit de lijst met geblokkeerde bronnen blijkt dat beide jquery scripts worden geblokkeerd door een instelling in de robots.txt.
Wat blijkt: de hele map /wp-includes/ wordt in de robots.txt file. Dit is schijnbaar een standaardinstelling van WordPress…
Het resultaat
Afgelopen week moedigde Matt Cutts (hoofd webspam bij Google) tijdens SMX Advanced iedereen aan om CSS & JavaScript bestanden niet meer te blokkeren zodat Googlebot websites exact kan indexeren.
Zo gezegd, zo gedaan. Na een simpele aanpassing in de robots.txt zie hieronder het resultaat:
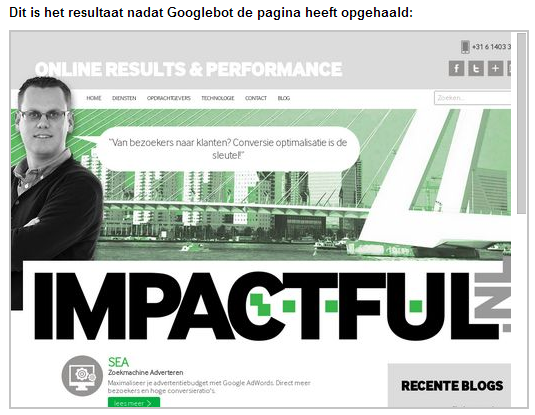
Voorbeeld 2: Google Authorship implementeren en indexeren
Zoals ik al eerder schreef is het ook mogelijk om fetchen als Google te gebruiken om nieuwe content of aanpassingen door te voeren in de Google index.
Als webmaster heb je twee opties om content in te dienen bij de index:
- Alleen deze URL crawlen (quotum van 500 URL’s per maand)
- Deze URL en de bijbehorende rechtstreekse links crawlen (quotum van 10 URL’s per maand)
Voor de meeste websites is dit quotum meer dan voldoende. Is dit niet het geval dan is het raadzaam om alleen die URL’s te laten crawlen die naar verwachting het meeste waarde toevoegen.
Op Impactful.nl had ik Google Authorship alleen ingesteld op blogposts. Nu zijn alle andere pagina’s natuurlijk ook van mijn hand dus is het logisch als rel=author naar mij verwijst. Vanzelfsprekend wil ik dat deze implementatie ook direct zichtbaar is in Google. Om dit voor elkaar te krijgen heb ik de pagina’s opnieuw ingediend bij de Google index.
SERP-snippets voor fetchen als Google:


SERP-snippets direct na fetchen als Google:
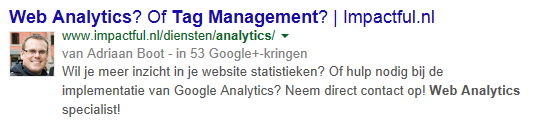

Enkele ogenblikken nadat de pagina’s opnieuw zijn ingediend bij de index waren, kwam mijn Google+ foto naar voeren in de zoekresultaten. Als webmaster heb je dus zelf in de hand wanneer Googlebot nieuwe of gewijzigde content op je website ontdekt.
Concluderend
Ik zou zeggen: profiteer vandaag nog van de mogelijkheden die deze simpele, maar toch enorm waardevolle, tool te bieden heeft! De enige voorwaarde is dat je een Google Webmaster Tools account hebt. Ik ga ervanuit dat iedereen die het einde van deze post leest al wel een GWT account heeft.
Is dit niet het geval dan ben ik heel benieuwd wat de reden hiervan is. Gebruik hiervoor de comments. Laat ook in de reacties weten waarvoor en wanneer jij pagina’s fetcht als Google en (opnieuw) laat indexeren door Google.
Marloes Smit says
Beste Adriaan,
Interessant artikel. Ik gebruik Fetchen als Google al een tijdje, maar zag inderdaad dat pagina’s gedeeltelijk geblokkeerd werden.
Heb jij dan de hele map /wp-includes/ uit je robots.txt gehaald?
Dank! Hoor het graag.
groeten Marloes
Adriaan Boot says
Hi Marloes,
Ik heb inderdaad de hele map /wp-includes/ uit de robots.txt gehaald. Uiteindelijk wil je dat de googlebot al je files zo goed mogelijk kan crawlen .
Groeten,
Adriaan
michel piedfort says
fetchen.
Dat, ik heb dit nu geprobeerd maar ik krijg niet de lijst van de foute url’s. Doe ik iets mis?
Michel
Adriaan Boot says
Hi Michel,
Heb je wel gekozen voor ophalen en weergeven?
Adriaan
Martijn says
Werkt dit ook als je nieuwe content sneller gecrawld wilt hebben, of sneller te kijken wat je SEO doet?
Adriaan Boot says
Absoluut! Nieuwe content kun je binnen no-time geïndexeerd krijgen via fetchen als Google.